Research Activities
Adaptive Calibration Policies in Digital Twins
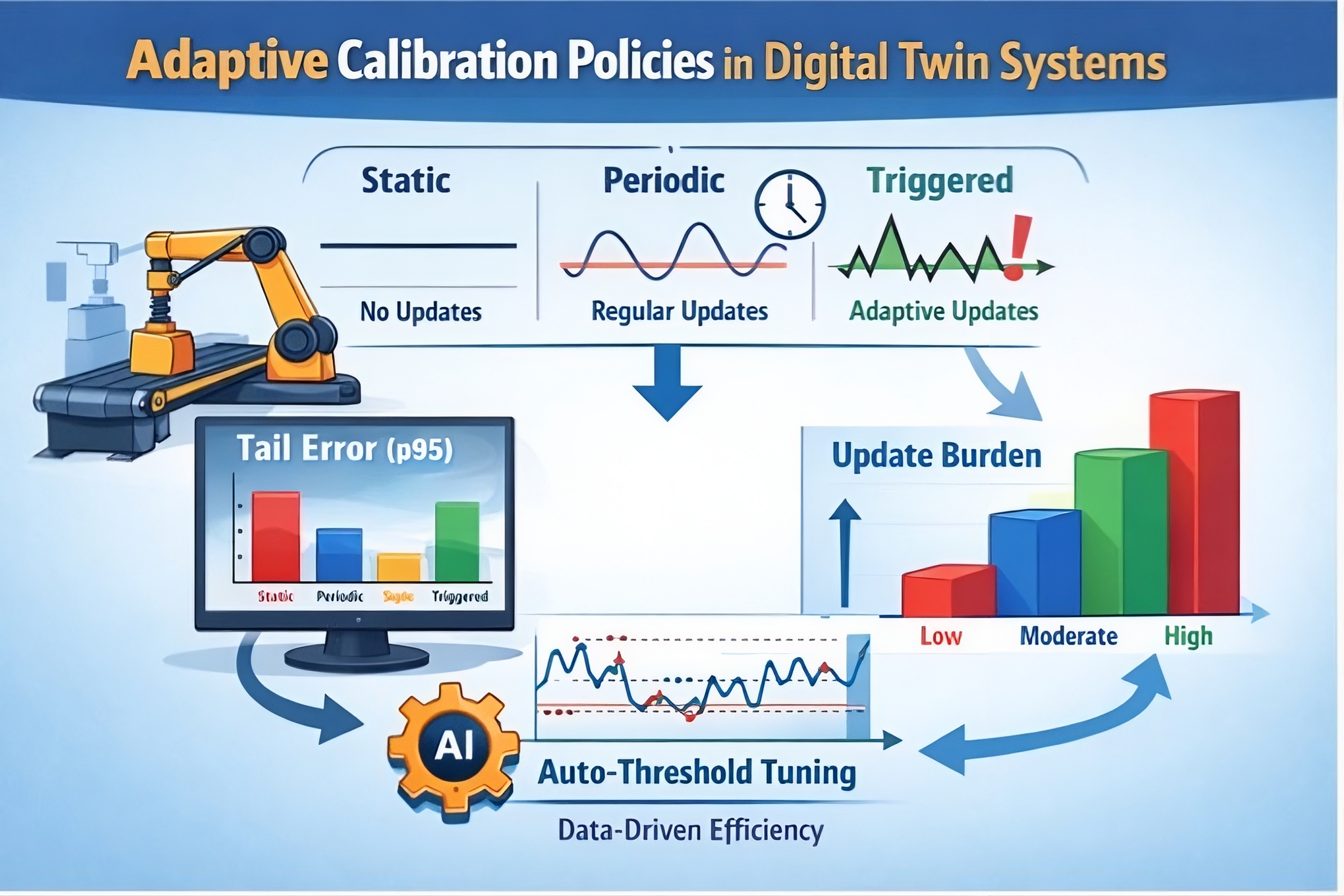 Digital twins (DTs) drift out of sync during real operations due to changing conditions (e.g., friction, wear, setup error), so reliability depends on when the DT is updated—not just how often. We evaluate three calibration policies—static, periodic, and triggered (threshold-based)—on a PyBullet workcell stream (T=1000, drift at [200, 500, 800]) using event alignment (recall/delay), tail risk (p95), and update cost. Results showed triggered updates can maintain low tail error while providing explainable, signal-driven update decisions, whereas periodic schedules may improve accuracy but can waste updates when drift is absent. Overall, DT reliability is best achieved by drift-aligned, risk-aware calibration that controls tail risk under operational constraints.
Digital twins (DTs) drift out of sync during real operations due to changing conditions (e.g., friction, wear, setup error), so reliability depends on when the DT is updated—not just how often. We evaluate three calibration policies—static, periodic, and triggered (threshold-based)—on a PyBullet workcell stream (T=1000, drift at [200, 500, 800]) using event alignment (recall/delay), tail risk (p95), and update cost. Results showed triggered updates can maintain low tail error while providing explainable, signal-driven update decisions, whereas periodic schedules may improve accuracy but can waste updates when drift is absent. Overall, DT reliability is best achieved by drift-aligned, risk-aware calibration that controls tail risk under operational constraints.
Human Neural Feedback-based Interactive Reinforcement Learning
![Gemini said A photographic illustration with an overlaid system diagram, titled 'Human Neural Feedback-based Interactive Reinforcement Learning,' details a method for training a robot with implicit human feedback. A person wearing an electroencephalogram (EEG) cap, identified by electrode locations (highlighted in the red box labeled 'EEG/ErrP→Reward/Penalty'), is shown making a physical hand gesture towards a dual-arm Baxter research robot. The workflow is split into a physical interaction loop (blue arrows) and a feedback/learning loop (red arrows). The physical loop includes: [1] Gesture (human motion), [2] Detect Gesture (camera observation by robot), [3] Action (robot positions a cup behind others), and [4] Feedback (human visually observes action outcome). The learning loop begins when the human's observation (Step 4) creates an Error-Related Potential (ErrP) brain state, labeled [5] 'EEG with ErrP' (with a red negative peak on a neural graph labeled 'Negative Reward Signal (e.g., ErrP)'). This signal is processed by a yellow-highlighted 'ErrP Classifier' [Step 1] (computer screen showing classification boundary) to create a scalar reward signal. Step [2] shows this signal (Reward/Penalty) sent from the classifier to the robot. Step [7] details the robot's 'RL (Q-learning)' module, where a Q-value is updated according to the formula: Q t+1 (s t ,a t )=Q t (s t ,a t )+αErrP. This updated Q-value (Step 6) informs future robot action-selection. The overall process is described by the yellow text box as a 'Reinforcement Learning (RL) process using human internal (e.g., neural) reward,' where the human internal state serves as a direct input to shape the robot's learning policy. The final result is the robot adapting its action (as shown in Step 3) based on implicit neural instructions.](_files/human-neural-feedbackirl.jpg) This project aims at developing agents that learn from a human’s brain signals (e.g., EEG/ERP) as an additional feedback channel beyond rewards defined by the environment. The system decodes neural markers of error recognition, surprise, workload, or confidence in real time and converts them into shaping rewards, policy constraints, or preference signals to accelerate learning and improve alignment with human intent. This enables adaptive, human-in-the-loop control in high-stakes settings where explicit labels are costly or slow (e.g., assistive robotics, neuroadaptive interfaces, safety-critical decision support). Key challenges include low SNR and nonstationarity of neural data, latency constraints, user variability, and ensuring robust, interpretable, and ethically governed adaptation.
This project aims at developing agents that learn from a human’s brain signals (e.g., EEG/ERP) as an additional feedback channel beyond rewards defined by the environment. The system decodes neural markers of error recognition, surprise, workload, or confidence in real time and converts them into shaping rewards, policy constraints, or preference signals to accelerate learning and improve alignment with human intent. This enables adaptive, human-in-the-loop control in high-stakes settings where explicit labels are costly or slow (e.g., assistive robotics, neuroadaptive interfaces, safety-critical decision support). Key challenges include low SNR and nonstationarity of neural data, latency constraints, user variability, and ensuring robust, interpretable, and ethically governed adaptation.
Explainable AI-based Shapley Additive Explanations for Remaining Useful Life Prediction
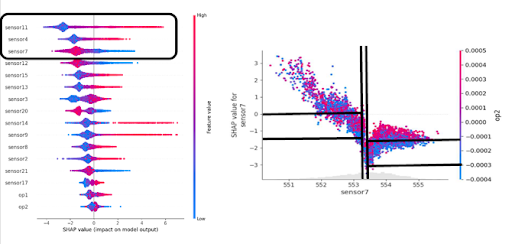 This study uses the NASA Turbofan Engine (C-MAPSS) dataset to build a data-driven model for Remaining Useful Life (RUL) prediction and to make its predictions transparent using explainable AI. It applies SHAP (Shapley Additive Explanations) to quantify how individual sensor features contribute to each RUL estimate, providing instance-level interpretability and feature importance. The resulting explanations help identify key degradation signatures and improve trust and decision support for predictive maintenance.
This study uses the NASA Turbofan Engine (C-MAPSS) dataset to build a data-driven model for Remaining Useful Life (RUL) prediction and to make its predictions transparent using explainable AI. It applies SHAP (Shapley Additive Explanations) to quantify how individual sensor features contribute to each RUL estimate, providing instance-level interpretability and feature importance. The resulting explanations help identify key degradation signatures and improve trust and decision support for predictive maintenance.
Data Augmentation in Cognitive States Recognition: Generative Models-based Approaches
This research aims to improve Deep Learning classifiers for EEG-based cognitive states recognition by generating synthetic EEG signals using Generative Models (GMs), representing data distributions, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). This study will solve not only the data scarcity problem in EEG experiment domains but also the overfitting problem of Deep Learning-based classifiers using EEG
Hyperscanning: Quantification Method for Inter-Brain Neural Synchrony
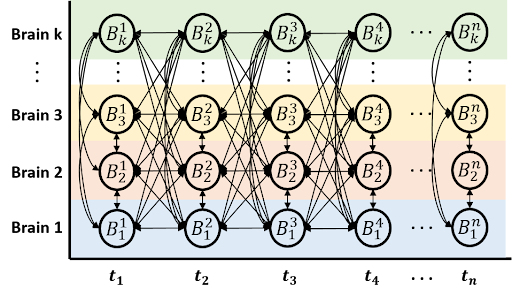 The objective of this research is to develop a computational framework that can quantify the degree of the inter-brain synchrony change over time. This study provides numerical convergence information between inter-brains. It helps to identify the consensus of information between agents in a specific paradigm like social interaction.
The objective of this research is to develop a computational framework that can quantify the degree of the inter-brain synchrony change over time. This study provides numerical convergence information between inter-brains. It helps to identify the consensus of information between agents in a specific paradigm like social interaction.
I-SMILE Smart Healthcare: Assessment of Upper Limb Motion Tracking Based on Wearable Inertial Sensors
The Smart Healthcare project is a research initiative to investigate and develop a new system for allowing physical therapists to remotely monitor the rehabilitation progress of their patients. The hardware component of this project includes an array of wearable, wireless sensors for monitoring upper limb range of motion, as well as trunk movement. The software component consists of an application to gather the motion data from the sensor arrays, process the data to recreate the patients’ movements, and then present the clinically relevant information for each patient to a therapist, with a special note made for any abnormalities found with the recorded motions.
Collaborative Brain-Computer Interface for People with Severe Motor Disabilities

The objective of this research is to investigate the collaborative behavior of people with motor disabilities (i.e., amyotrophic lateral sclerosis, ALS) using a collaborative BCI system that utilizes steady-state visually evoked potentials (SSVEPs). The NC State Brainbot BCI was used as a testbed for the research.
Initial Assessment of Hand Orthosis: Implications for Brain-Computer Interface-Driven Motor Rehabilitation
 The objective of this research is to address a general lack of understanding of the wearing comfort and usability of the hand orthosis as well as efficacy of brain-computer interface (BCI)-driven orthosis as a potential rehabilitation tool. Findings from this study will also allow us to conduct long-term rehabilitation studies with stroke patients who have severe motor impairments.
The objective of this research is to address a general lack of understanding of the wearing comfort and usability of the hand orthosis as well as efficacy of brain-computer interface (BCI)-driven orthosis as a potential rehabilitation tool. Findings from this study will also allow us to conduct long-term rehabilitation studies with stroke patients who have severe motor impairments.
Functional Electrical Stimulation (FES) based Brain-Computer Interfaces (BCIs) for Rehabilitation of Stroke Patients
 The objective of this research is to validate if paralyzed multiple limbs can be controlled in real-time by a Motor Imagery (MI) based Brain-Computer Interface (BCI) with Functional Electrical Stimulation (FES) and to improve system accuracy based on subject-specific reference and stimulation time epochs. This research study will be extended to improve fine motor control of the hands.
The objective of this research is to validate if paralyzed multiple limbs can be controlled in real-time by a Motor Imagery (MI) based Brain-Computer Interface (BCI) with Functional Electrical Stimulation (FES) and to improve system accuracy based on subject-specific reference and stimulation time epochs. This research study will be extended to improve fine motor control of the hands.
Direct Bidirectional Brain-to-Brain Communication in Humans via Non-Invasive Neurotechnology
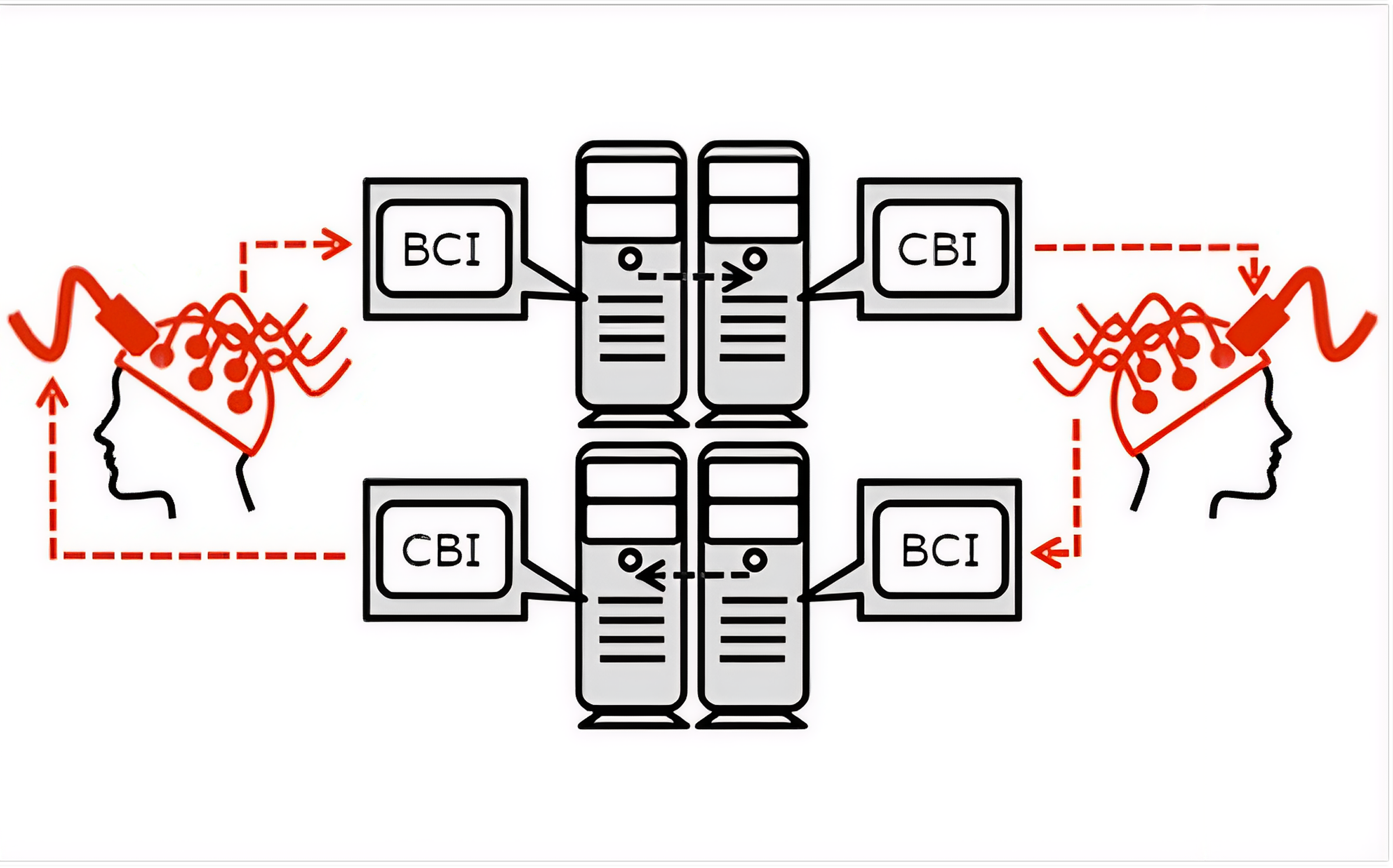 This project seeks to expand the newly budding field of B2BI by establishing one of the first direct bidirectional systems. What this means is that we aim to transmit information directly between two brains using brain recording and neuromodulation simultaneously. Two participants will be able to communicate simple information between each other using nothing other than thought (no speech or touch or sight involved).
This project seeks to expand the newly budding field of B2BI by establishing one of the first direct bidirectional systems. What this means is that we aim to transmit information directly between two brains using brain recording and neuromodulation simultaneously. Two participants will be able to communicate simple information between each other using nothing other than thought (no speech or touch or sight involved).
